Simon Willison'dan Claude Token Counter'a Model Karşılaştırma Modu
Simon Willison yine iş başında. Bu sefer Claude Token Counter'ına model karşılaştırma özelliği eklemiş. Hacker News'te 90 puan almış, 30 yorumla tartışılmış. Demek ki insanlar bu konuya kafa yoruyor - ki hakları da var.
Token Sayma NEden Bu Kadar Önemli?
Bakın, LLM'lerle çalışıyorsanız tokenler sizin paranız. Her API çağrısında ne kadar token harcadığınızı bilmezseniz, ay sonunda fatura geldiğinde şaşırırsınız. Ben birkaç ay önce bir proje için Claude'u entegre ederken bu hesabı iyi yapamamıştım - öyle bir fatura geldi ki, neredeyse monitörü yumruklayacaktım.
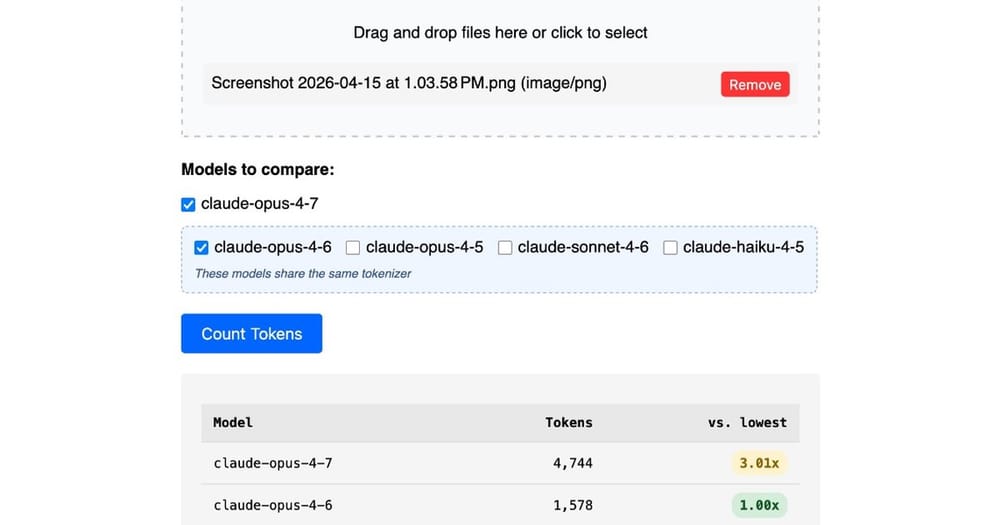
İşte tam burada Simon Willison'ın Claude Token Counter'ı devreye giriyor. Araç zaten token sayımı yapıyordu, ama şimdi gelen özellik asıl bomba: farklı Claude modellerini karşılaştırabiliyorsunuz.
Model Karşılaştırması Nasıl İşliyor?
Diyelim ki bir prompt hazırladınız. Claude 3.5 Sonnet mi kullanmalısınız, yoksa Claude 3 Opus mu? Belki de Claude 3 Haiku yeterli gelir? Her birinin token maliyeti farklı, performansı da farklı.
Şimdiye kadar bunu test etmek için ya manuel olarak API'yi çağırıp sonuçları karşılaştırmanız gerekiyordu (vakit kaybı), ya da kafadan "şöyle olur herhalde" diye tahmin yürütüyordunuz (daha da kötü). Willison'ın aracı bu süreci basitleştiriyor - aynı prompt için farklı modellerin token kullanımını yan yana görebiliyorsunuz.
Pratik açıdan düşünün: 1000 kullanıcılı bir chatbot yapıyorsunuz. Her kullanıcı günde ortalama 10 mesaj gönderiyor. Model seçimi yanlışsa, aylık binlerce dolar fazladan ödeyebilirsiniz. Ya da tam tersi - çok ucuz model seçip kalite kaybedebilirsiniz.
Hacker News Kitlesi Ne Diyor?
30 yorum var şu ana kadar. Yorumları incelerken şunu fark ettim: insanlar sadece token sayısıyla ilgilenmiyor, aynı zamanda farklı modellerin aynı prompt için ne kadar farklı cevap verdiğini de merak ediyor.
Birisi şöyle yazmış (parafraz ediyorum): "Token sayısı önemli ama output kalitesi daha önemli. Ucuz model 100 token az harcasa bile, sonucu kullanılamıyorsa ne anlamı var?"
Haklı tabii. Bence burada önemli olan şu: Willison'ın aracı size veriyi veriyor, kararı siz veriyorsunuz. Hangi modelin ne kadar token harcadığını görüyorsunuz, sonra çıktı kalitesine bakıp dengeli bir karar alıyorsunuz.
Gerçek Dünyada Kullanım Senaryoları
- Prototipleme aşaması: Hızlı test için Haiku kullanıp, production'a geçerken Sonnet'e yükseltebilirsiniz
- Batch işlemler: Binlerce dökümanı işleyecekseniz, model farkı astronomik maliyet farkı yaratabilir
- Hybrid yaklaşım: Basit sorular için ucuz model, karmaşık görevler için güçlü model - ama bunu test etmeniz lazım
- Budget planlaması: Aylık API harcamanızı önceden tahmin edebilirsiniz
Simon Willison Kim ki?
Bilmeyenler varsa - ki olmamalı ama - Simon Willison Django'nun kurucu geliştiricilerinden biri. Yıllardır açık kaynak dünyasında aktif, özellikle veri gazeteciliği ve şimdi de LLM araçları konusunda çok üretken. Adamın blogu zaten bir referans kaynağı.
Bu tür araçları geliştirip ücretsiz sunması da takdir edilesi. Token Counter gibi şeyler büyük şirketlerin paraya bağladığı premium özellikler olabilir (bakın OpenAI'ın Playground'unda bile bazı şeyler eksik), ama Willison bunu community'ye açık şekilde sunuyor.
Maliyet Optimizasyonu Artık Mecburi
2024'te LLM'ler yeni çıkmıştı, herkes test ediyordu, maliyet çok da önemlenmiyordu. 2026'ya geldik - artık production seviyesinde uygulamalar var, ciddi kullanıcı sayıları var. Maliyet optimizasyonu lüks değil, zorunluluk.
Örnek vereyim: Geçen hafta bir startup'la konuşuyordum, ayda 8 bin dolar Claude API'sine veriyorlarmış. Dedim "Model seçimini optimize ettiniz mi?" Cevap: "Hepsinde Opus kullanıyoruz, en iyisini istiyoruz." Sonra birlikte baktık, işlerin %60'ı Sonnet'le halloluyormuş. Potansiyel tasarruf: ayda yaklaşık 3-4 bin dolar.
İşte bu yüzden Willison'ın aracı gibi şeyler önemli. Gerçek verilerle karar almanızı sağlıyor.
Nasıl Kullanılır?
Araç web tabanlı, Simon Willison'ın blogundan erişebilirsiniz. Prompt'unuzu giriyorsunuz, hangi modelleri karşılaştırmak istediğinizi seçiyorsunuz, sonuç olarak her modelin kaç token harcayacağını görüyorsunuz.
Basit ama etkili. Süslü arayüz yok, gereksiz özellik yok. İşini yapıyor - bence araç geliştirmenin altın standardı bu.
Sektörün Gidişatı
Bu tür araçların çoğalması, LLM ekosisteminin olgunlaştığını gösteriyor. İlk başta herkes "Bu ne kadar havalı!" diyordu, şimdi "Bu ne kadar verimli?" diye soruyor.
Anthropic, OpenAI, Google - hepsi farklı fiyat katmanlarında modeller sunuyor. Hangisini, ne zaman kullanacağınızı bilmek rekabet avantajı. Özellikle bootstrap bir startup iseniz, her dolar sayılıyor.
Tabii büyük oyuncular da boş durmuyor. OpenAI'ın batch API'si var, Anthropic'in caching mekanizması var. Ama kullanıcı tarafında da bu araçlara ihtiyaç var - provider'lar her zaman sizin çıkarınızı düşünmeyebilir.
Sonuç (Ama Klişe Olmayan Türden)
90 puan Hacker News'te boşuna değil. Community bir şeyin işine yarayacağını anladığında tepki gösteriyor zaten. Simon Willison'ın Claude Token Counter'ına eklediği model karşılaştırma özelliği, tam zamanında gelmiş bir güncelleme.
Eğer Claude API kullanıyorsanız - ki kullanıyorsanız çünkü 2026'da LLM kullanmayan kim kaldı - bir bakın bu araca. En azından şu anki model seçiminizin mantıklı olup olmadığını test edin. Belki binlerce dolar tasarruf edeceksiniz, belki de "tamam, doğru modeli kullanıyormuşuz" diyip içiniz rahat edecek.
Her iki durumda da kazançlısınız.
Kaynak: Simon Willison Blog